starwars %>%
select(everything())Dplyr
R
dplyr
tidyverse
Обзор основного функционала пакета dplyr
Выполним установку пакета dplyr и загрузим набор данных starwars
```{r}
library(dplyr)
starwars <- dplyr::starwars
```tidy-select
Пакет tidyselect - это серверная часть таких функций, как dplyr::select() или dplyr::pull(), а также нескольких глаголов tidyr. Это позволяет создавать глаголы выбора, которые совместимы с другими пакетами tidyverse.
Конечно логичнее было разместить раздел tidyselect в части выборки данных -> Столбцы, но tidyselect имеет гораздо большее значение и может применяться не только в select.
tidyselect поддерживает базовые функции R по выборке:
:для выбора диапазона последовательных переменных.!для получения дополнения к набору переменных.& и |для выбора пересечения или объединения двух наборов переменных.c()для объединения выделений.
Также можно использовать функции помощи в выборке, для конкретных столбцов
everything()- выбирает все столбцы, обычно применяется с другими операторами tidyselectlast_col()- выбирает последнюю переменную
Для выборки столбцов сопоставляя шаблоны в их именах:
starts_with: название столбца начинается с точного префиксаends_with: название столбца заканчивается на точный суффиксcontains: название столбца содержит символmatches: название столбца соответствует регулярному выражениюnum_range: поиск занумерованных столбцов, например, «V1, V2, V3…»all_of(): точный поиск по значениям, проверяет наличие значенийany_of(): поиск без проверки наличия значений, используется, чтобы убедиться, что столбец удаленone_of: название столбца соответствует одному из вариантовwhere(): условие функции должно быть True
Сделать строки с блоками кода на подобии тех, что использую в соединениях и наглядно показать как работают и чем отличаются функции помощи
Рассмотрим подробнее функции помощи
Функции выбора
everything
everything(vars = NULL) - выбирает все столбцы, обычно применяется с другими операторами tidyselect
vars - Символьный вектор имен переменных. Если не указано, переменные берутся из текущего контекста выбора (как установлено такими функциями, как select() или pivot_longer()).
last_col
last_col(offset = 0L, vars = NULL) - выбирает последнюю переменную
offset - устанавливает какое количество столбцов с конца нужно пропустить
starwars %>%
select(1:last_col(9))starwars %>%
select(last_col(9))Функции поиска по шаблону
Аргументы функций поиска по шаблону:
match- Вектор символов. Если длина > 1, берется объединение совпадений. Для starts_with(), ends_with() и contains() это точное совпадение. Для matches() это регулярное выражение и может быть шаблоном stringr.ignore.case- Если значение по умолчанию равно TRUE, регистр игнорируется при сопоставлении именvars- Символьный вектор имен переменных. Если не указано, переменные берутся из текущего контекста выбора (как установлено такими функциями, как select() или pivot_longer()).prefix, suffix- Префикс/суффикс, добавленный до/после числового диапазонаrange- Последовательность целых чисел, например 1:5width- Необязательный аргумент, “ширина” числового диапазона. Например, диапазон из 2 дает “01”, диапазон из трех “001” и т.д
starts_with
starts_with() - отбирает те столбцы название которых начинается с точного префикса
starts_with(match, ignore.case = TRUE, vars = NULL)
В функции starts_with() есть возможность задать мульти префикс, в этом случае порядок столбцов будет зависеть от порядка указания префиксов.
# отберем столбцы, название которых начинается на символ «h».
starwars %>%
select(starts_with("h"))# отберем столбцы, название которых начинается на символы "b" и «h».
starwars %>%
select(starts_with(c("b", "h")))ends_with
ends_with(match, ignore.case = TRUE, vars = NULL) - отбирает те столбцы название которых заканчивается на точный суффикс
В функции ends_with() есть возможность задать мульти суффикс, в этом случае порядок столбцов будет зависеть от порядка указания суффиксов.
# отберем столбцы, название которых заканчивается на слово «color».
starwars %>%
select(ends_with("color"))# отберем столбцы, название которых заканчивается на слова "year" и «color».
starwars %>%
select(ends_with(c("year", "color")))contains
contains(match, ignore.case = TRUE, vars = NULL) - отбирает те столбцы название которых содержит в названии символ/ы
В функции contains() есть возможность задать несколько символьных шаблонов, в этом случае порядок столбцов будет зависеть от порядка указания символов.
# отберем столбцы, название которых содержит букву «а».
starwars %>%
select(contains('a'))# отберем столбцы, название которых содержит буквы «m» и "f".
starwars %>%
select(contains(c('m', 'f')))matches
Функции starts_with(), ends_with() и contains() не используют регулярные выражения. Для выбора с помощью регулярного выражения нужно использовать matches()
matches(match, ignore.case = TRUE, perl = FALSE, vars = NULL) - отбирает те столбцы название которых соответствует регулярному выражению
# отберем столбцы, название которых соответствует регулярному выражению
starwars %>%
select(matches('[rne]_color'))num_range
num_range(prefix, range, suffix = "", width = NULL, vars = NULL) - отбирает те столбцы название которых соответствует префиксу и числовому диапозону
Функции starts_with() и num_range() похожи, только первая ищет по префиксу, то num_range() отбирает по числовому диапозону внутри этого префикса.
Сравним эти функции на фрейме данных billboard, который содержит столбцы одиннаковым префиксом + номер столбца
# отбираем столбцы с префиксом "wk"
billboard %>%
select(starts_with("wk"))# отбираем столбцы с префиксом "wk" и числовым диапозоном от 2 до 5
billboard %>%
select(num_range("wk", 2:5))Функции выбора по символьному вектору
all_of
all_of(x) - предназначен для строгого отбора. Если какая-либо из переменных в символьном векторе отсутствует, выдается сообщение об ошибке
var <- c('name', 'mass')
starwars %>%
select(all_of(var))```{r}
# Если какая-либо переменная отсутствует во фрейме данных, это ошибка
var <- c('name', 'mass', 'class')
starwars %>%
select(all_of(var))
# Error in `select()`:
# ! Problem while evaluating `all_of(var)`.
# Backtrace:
# 1. starwars %>% select(all_of(var))
# 3. dplyr:::select.data.frame(., all_of(var))
# Error in select(., all_of(var)) :
```any_of
any_of(x, ..., vars = NULL) - не проверяет наличие отсутствующих переменных. Это особенно полезно при отрицательном выборе, когда вы хотите убедиться, что переменная удалена
# Проверяем, что столбец отсутствует во фрейме
var <- c('class')
starwars %>%
select(any_of(var))# Удаляем из фрейма столбцы
# Даже вызвав одну функцию несколько раз ошибки не будет
var <- c('name', 'mass')
starwars %>%
select(-any_of(var)) %>%
select(-any_of(var))Выбор через функцию
where
where(fn) - Применяет функцию ко всем переменным и выбирает те, для которых функция возвращает значение TRUE
Внутри функции можно создавать анонимные функции подобно тем, что создаются в пакете purrr, рассмотрим разные варианты реализации одной и той же логики
# отбираем только числовые столбцы
iris %>%
select(where(is.numeric))# отбираем только числовые столбцы
iris %>%
select(where(function(x) is.numeric(x)))# отбираем только числовые столбцы
iris %>%
select(where(~ is.numeric(.x)))# отбираем только числовые столбцы # у которых стреднее больше 3.5
iris %>%
select(where(~ is.numeric(.x) && mean(.x) > 3.5))Выборка данных
В R возможно делать выборку столбцов разными стособами. Просто перечислить названия столбцов или их номера, перечислить какие столбцы не нужно выводить или выводить столбцы с именем соответствующим определенному условию.Выбор с использованием tidyselect рассмотрели выше, теперь рассмотрим ещё пару стандартных способов отбора столбцов.
Вернуть вектор
Если нужно вернуть столбец не как таблицу, а вектор, то делаем это через pull
starwars %>%
pull('name') [1] "Luke Skywalker" "C-3PO" "R2-D2"
[4] "Darth Vader" "Leia Organa" "Owen Lars"
[7] "Beru Whitesun lars" "R5-D4" "Biggs Darklighter"
[10] "Obi-Wan Kenobi" "Anakin Skywalker" "Wilhuff Tarkin"
[13] "Chewbacca" "Han Solo" "Greedo"
[16] "Jabba Desilijic Tiure" "Wedge Antilles" "Jek Tono Porkins"
[19] "Yoda" "Palpatine" "Boba Fett"
[22] "IG-88" "Bossk" "Lando Calrissian"
[25] "Lobot" "Ackbar" "Mon Mothma"
[28] "Arvel Crynyd" "Wicket Systri Warrick" "Nien Nunb"
[31] "Qui-Gon Jinn" "Nute Gunray" "Finis Valorum"
[34] "Jar Jar Binks" "Roos Tarpals" "Rugor Nass"
[37] "Ric Olié" "Watto" "Sebulba"
[40] "Quarsh Panaka" "Shmi Skywalker" "Darth Maul"
[43] "Bib Fortuna" "Ayla Secura" "Dud Bolt"
[46] "Gasgano" "Ben Quadinaros" "Mace Windu"
[49] "Ki-Adi-Mundi" "Kit Fisto" "Eeth Koth"
[52] "Adi Gallia" "Saesee Tiin" "Yarael Poof"
[55] "Plo Koon" "Mas Amedda" "Gregar Typho"
[58] "Cordé" "Cliegg Lars" "Poggle the Lesser"
[61] "Luminara Unduli" "Barriss Offee" "Dormé"
[64] "Dooku" "Bail Prestor Organa" "Jango Fett"
[67] "Zam Wesell" "Dexter Jettster" "Lama Su"
[70] "Taun We" "Jocasta Nu" "Ratts Tyerell"
[73] "R4-P17" "Wat Tambor" "San Hill"
[76] "Shaak Ti" "Grievous" "Tarfful"
[79] "Raymus Antilles" "Sly Moore" "Tion Medon"
[82] "Finn" "Rey" "Poe Dameron"
[85] "BB8" "Captain Phasma" "Padmé Amidala" Столбцы
Перечисление
starwars %>%
select(name)Отрицательное перечисление
Если нужно указать какой столбец не включать в выборку то ставится знак минус:
starwars %>%
select(-c(name, mass))По номерам
Или можно указать номера столбцов
starwars %>%
select(1, 2)Упорядочивание столбцов
relocate
relocate(.data, …, .before = NULL, .after = NULL) - смена позиции столбца, использует иснтаксис select(включая tidy-select) чтобы легко перемещать один или несколько столбоц за один раз
.data- указываем, что переместить.before- перемещение до и указваем столбец или выражение tidy-select.after- перемещение после и указваем столбец или выражение tidy-select
df <- tibble(a = 1, d = "a", b = 1, f = "a")
df# ставим стоблец f в начало
df %>% relocate(f)# ставим стоблец a после d
df %>% relocate(a, .after = d)# ставим стоблец f перед b
df %>% relocate(f, .before = b)И ещё несколько вариантов используя tidy-select
# числовые столбцы в конец
df %>%
relocate(where(is.numeric),
.after = last_col())# если есть столбцы с такими названиями
# то их ставим вначало
df %>%
relocate(any_of(c("a", "e", "i", "o", "u")))# числовые столбцы после символьных
df %>%
relocate(where(is.numeric),
.after = where(is.character))Строки
Уникальные значения
starwars %>%
distinct(sex)Случайные строки
sample_n
Возвращаем n - случайных строк
starwars %>%
sample_n(5)sample_frac
Если нужно указать долю строк из общего числа, которые должны быть в итоговой таблице, то используем sample_frac. Например, при параметре 0.5 вернется половина строк из таблицы, выбранные случайным образом.
starwars %>%
sample_frac(0.1)Срезы
Функции slice позволяют сделать срез из выборки данных по условию, рассмотрим аргументы функций:
n, prop- задает количество (n) или пропорцию (prop) выбираемых строк, по умолчаниюn = 1. Если указано отрицательное значениеnилиprop, указанное количество или пропорция строк будут удалены. Еслиnбольше, чем количество строк в группе (илиprop > 1), результат будет автоматически усечен до размера группы. Если доля размера группы не дает целого числа строк, абсолютное значениеprop * nrow(.data)округляется в меньшую сторону.with_ties- указывает нужно ли включать в выборку дубликаты по выбранному столбцуweight_by- задает взвешенную случайную выборку фрейма данных т.е. задает вероятность включения каждой строки в результирующее подмножество, которая будет пропорциональна значениям в указанном столбце. Указав вес столбца, можно гарантировать, что более важные строки с большей вероятностью попадут в выборку. Используется когда нужно сделать репрезентативную выборку для исследования.replace- указывает нужно ли переписывать текущий фрейм, если значение TRUE, то текущий фрейм сразу заменяется результатом выборки, если FALSE, то выборка возвращается как новый фрейм данных, без изменения исходного фрейма.
Создадим набор данных для описания возможностей работы со срезами
df <- tribble(
~key, ~val_y, ~val_x,
1, "y1", 6,
2, "y2", 1,
3, "y3", 3,
4, "y4", 9,
5, "y5", 2,
6, "y6", 7,
7, "y7", 4,
8, "y8", 10,
9, "y9", 5,
9, "y10", 8
)
dfslice
slice(.data, ..., .preserve = FALSE)
Функция slice() позволяет выбирать строки из фрейма данных на основе их положения. Функция принимает два аргумента, первый из которых является фреймом данных, а второй - диапазоном строк для выбора. Диапазон задается с помощью оператора : и может быть одним значением или диапазоном значений.
df %>%
slice(1:n()) df %>%
slice(1:4) df %>%
slice(1L)slice_head
slice_head(.data, ..., n, prop)
Функция slice_head() аналогична функции slice(), но выбирает первые n строк фрейма данных. Функция принимает два аргумента, первый из которых является фреймом данных, а второй - количеством строк для выбора.
df %>%
slice_head(n = 5) df %>%
slice_head(prop = 0.2) slice_tail
slice_tail(.data, ..., n, prop)
Функция slice_tail() аналогична функции slice(), но выбирает последние n строк фрейма данных. Функция принимает два аргумента, первый из которых является фреймом данных, а второй - количеством строк для выбора.
df %>%
slice_tail(n = 5) df %>%
slice_tail(prop = 0.1) slice_min
slice_min(.data, order_by, ..., n, prop, with_ties = TRUE)
Функция slice_min() используется для выбора строк с минимальными значениями указанного столбца.
df %>%
slice_min(key, n = 2) slice_max
slice_max(.data, order_by, ..., n, prop, with_ties = TRUE)
Функция slice_max() используется для выбора строк с максимальными значениями указанного столбца. Функция принимает аргументы, первый из которых является фреймом данных, а второй - столбцом для выбора.
df %>%
slice_max(key, n = 3) df %>%
slice_max(key, n = 1, with_ties = T) df %>%
slice_max(key, n = 1, with_ties = F) slice_sample
slice_sample(.data, ..., n, prop, weight_by = NULL, replace = FALSE)
Функция slice_sample() используется для выбора случайной выборки строк из фрейма данных. Функция принимает аргументы, первый из которых является фреймом данных, а второй - количеством строк для выбора.
df %>%
slice_sample(n = 4) df %>%
slice_sample(n = 4, weight_by = val_x) Фильтрация
По логическому условию
starwars %>%
filter(mass > 50)#комбинировать несколько условий можно с помощью & и |:
starwars %>%
filter(mass > 50 & height > 170)Конструировать логические условия можно и другими операторами:
>=<=is.na!is.na%in%!betweennearxor
starwars %>%
filter(skin_color %in% c('fair', 'green'))between
Оператор between на самом деле сокращение от следующего условия:
x >= left & x <= right
Чтобы им воспользоваться, нужно указать:
x- переменную по которой надо фильтроватьleft- нижнюю границу диапозонаright- верхнюю границу диапозона
Отфильтруем персонажей звездных войн по росту в диапозоне от 100 до 155 сантиметров.
starwars %>%
filter(between(height, 100, 155))near
Оператор near равнозначен оператору сравнения ==, его рекомендуется применять для сравнения чисел в плавающей запятой, из-за возможности указать допуск в точности сравнения.
Допуски в сравнении задаются через атрибут tol с использованием числовых характеристик .Machine, например:
near(x, y, tol = .Machine$double.eps^0.5)
.Machine
.Machine - это переменная, содержащая информацию о числовых характеристиках машины, на которой запущен R, таких как наибольшее двоичное или целое число и точность машины.
Пример использования:
near(sqrt(2) ^ 2, 2)[1] TRUEСортировка
Для сортировки в языке есть достаточно широкие возможности. Вот самые основные виды сортировки:
По возрастанию
starwars %>%
arrange(mass)По убыванию
# сортировка по убыванию
starwars %>%
arrange(desc(mass))По нескольким столбцам
# сортировка по нескольким столбцам
starwars %>%
arrange(height, desc(mass))Расширенная сортировка
При сортировке можно использовать вспомогательные функции для select, только внутри функции across
starwars %>%
arrange(across(ends_with('_color'), desc))Вычисляемые столбцы
mutate
mutate(.data, ..., .by = NULL, .keep = c("all", "used", "unused", "none"), .before = NULL, .after = NULL)
Функция создает новый столбец на основе существующих переменных, а также может изменяет текущий столец (если имена равны) или удалять столбцы (устанавливая их значение равным NULL)
Аргументы:
.by- пока статус в жизненном цикле пакета [Experimental], будет альтернативой group_by().before \ .after- указывает место где расположить созданный\измененный столбец, этот агрумент также рассматривался в функции relocate.keep- указывает какие столбцы останутся в выходных данных после применения функцииall- сохраняет все столбцы из .data, используется по умолчаниюused- сохраняет только столбцы, используемые в функции, чтобы создать новый столбец. Это полезно для проверки работы, так как при этом входные и выходные данные отображаются параллельноunused- сохраняет только те столбцы, в которые не используется в функции, чтобы создать новые столбцы. Это полезно, если вы создаете новые столбцы, но столбцы, использованные для их создания, больше не нужныnone- сохраняет только группирующие переменные и столбцы созданные с помощью mutate
Рассмотрим простой пример создания нового столбца:
starwars %>%
select(name, height, mass) %>%
mutate('coef' = mass/height, .keep = "all")starwars %>%
select(name, height, mass) %>%
mutate('coef' = mass/height, .keep = "used")starwars %>%
select(name, height, mass) %>%
mutate('coef' = mass/height, .keep = "unused")starwars %>%
select(name, height, mass) %>%
mutate('coef' = mass/height, .keep = "none")С mutate применяются следующие функции:
- Оконные функции:
- lead(), lag()
- dense_rank(), min_rank(), percent_rank(), row_number(), cume_dist(), ntile()
- cumsum(), cummean(), cummin(), cummax(), cumany(), cumall()
- Обработка Null: na_if(), coalesce()
- Условные функции: if_else(), recode(), case_when()
rename | rename_with
rename(.data, ...) - переименновывает отдельные столбцы
rename_with(.data, .fn, .cols = everything(), ...) - переименновывает несколько столбцов с помощью функции
.cols - использует синтаксис tidy-select
Приведем простые примеры изменения наименований, в первом случае через функцию rename переименуем mass на weight, во втором все имена заканчивающиеся на “…color” сделаем верхним регистром
starwars %>%
select(name, height, mass) %>%
rename(weight = mass)starwars %>%
select(name, hair_color, skin_color, eye_color) %>%
rename_with(toupper, ends_with("color"))across
Функция позволяет применить одно и то же преобразование к нескольким столбцам
across(.cols, .fns, ..., .names = NULL, .unpack = FALSE)
Аргументы функции:
.cols- столбцы к которым нужно применить функцию, для выбрки доступен tidyselect.fns- применяемая функция.names- спецификация имен после применения функции, можно использовать {.col} для обозначения имени выбранного столбца и {.fn} для обозначения имени применяемой функции. По умолчанию “{.col}” для случая с одной функцией и “{.col}_{.fn}” для случая, когда для .fns используется список функций.
Пример с mutate:
Выберем несколько числовых столбцов и применим к ним округление
starwars %>%
mutate(across(c(2,3), round) )Пример с summarise:
В этом примере выберем два числовых столбца, применим к ним функции среднего и стандартного отклонения, также зададим спецификацию имен как: “название_столбца.название_функции”
starwars %>%
group_by(skin_color) %>%
summarise(
across(c(height, mass), list(mean = mean, sd = sd), .names = "{.col}.{.fn}"))if_any | if_all
Функции применяют одну и ту же функцию к нескольким столбцам и объединяют результаты в единый логический вектор
if_any(.cols, .fns, ..., .names = NULL) - имеет значение TRUE, когда предикат имеет значение TRUE для любого из выбранных столбцов
if_all(.cols, .fns, ..., .names = NULL) - имеет значение TRUE, когда предикат имеет значение TRUE для всех выбранных столбцов
Выполним три запроса: - базовый запрос, чтобы сформировать первоначальную выборку - второй запрос в котором применим функцию if_any - третий запрос в котором применим функцию if_all
Для обоих функций условия будут идентичные: во всех столбцах с типом double отбираем строки со значениями меньше 40.
starwars %>%
select(name, mass, birth_year) %>%
slice(1:10)starwars %>%
select(name, mass, birth_year) %>%
slice(1:10) %>%
filter(if_any(where(is.double), ~ . < 40))starwars %>%
select(name, mass, birth_year) %>%
slice(1:10) %>%
filter(if_all(where(is.double), ~ . < 40))Оконные функции
Если вы привыкли писать код на SQL, то при упониминании оконной функции в голове возникает следующая модель:
```{sql}
Select *
,SUM(col_1) # любая агрегатная функция
OVER ( # ключевое слово описания окна
PARTITION BY col_2 # формируем группы
ORDER BY col_3 # сортируем данные внутри группы
RANGE | ROWS | GROUPS UNBOUNDED PRECEDING # задаем начало и конец рамки окна
)
From table
```Переходя на R нужно переключиться на другие концепции, но постоянно будут возникать вопросы, наподобии: понятно как это сделать на SQL, но как это реализовать в концепции языка R?
Попробуем разобраться как переложить на концепцию на синтаксис языка R.
Для этого нужно перевести набор данных во временную таблицу, как будто это таблица из базы данных. У такого преобразования есть особенности, перевести можно набор данных, который содержит столбцы с поддерживаемыми типами данных в базе данных.
Поэтому неполучится перевести во временную таблицу набор starwars как есть из-за того, что он содержит тип list, сначала исключим из выборки столбцы с данным типом и преобразуем набор:
library(dbplyr, warn.conflicts = FALSE)
library(slider)
my_db <- DBI::dbConnect(RSQLite::SQLite(), ":memory:")
starwars_db <- copy_to(my_db, starwars %>% select(!where(is.list)), name = "starwars_db", overwrite = FALSE)И уже после этого можно смотреть как выглядит запрос на языке R в терминах SQL, например:
starwars_db %>%
arrange(mass) %>%
filter(species == 'Human') %>%
show_query()<SQL>
SELECT *
FROM `starwars_db`
WHERE (`species` = 'Human')
ORDER BY `mass`Функция show_query поможет проверить запрос в более привычном виде если это необходимо.
Формирование окна функции
Хотя функции dplyr обеспечивают больший функционал оконных функций, однако бывает необходимость выполнить более изощеренный сценарий, для таких случаев можно воспользоваться backend пакетом dbplyr.
А имено функциями:
window_order- задает сортировку, можно пользоваться привычным arrangewindow_frame- задает рамки окна
starwars_db %>%
#первый запрос
window_frame(0, 2) %>%
arrange(mass) %>%
mutate(z = mean(height), .by = gender) %>%
# второй запрос
window_frame(-2, 0) %>%
arrange(height) %>%
mutate(s = sum(mass), .by = homeworld) %>%
show_query()<SQL>
SELECT
*,
SUM(`mass`) OVER (PARTITION BY `homeworld` ORDER BY `height` ROWS 2 PRECEDING) AS `s`
FROM (
SELECT
*,
AVG(`height`) OVER (PARTITION BY `gender` ORDER BY `mass` ROWS BETWEEN CURRENT ROW AND 2 FOLLOWING) AS `z`
FROM `starwars_db`
)Далее рассмотрим функции предоставляемые пакетом dplyr
Offset
Функции позволяющие расчитать смещение по строкам
Аргументы функций
x- вектор, который будем перебиратьn- положительное число, задающее смещение относительно текущей строки, по умолчанию единицаdefault- если при смещении не найдено значение, то по умолчанию ставится Null, можно задать своё значениеorder_by- необязательное условие, сортировки вектора по дополнительному вектору, после применения смещения, т.е. сначала применили смещение, а потом отсортировали результат
lag
Функция задает смещение назад по вектору
lag(x, n = 1L, default = NULL, order_by = NULL, ...)
Рассмотрим смещение с разным набором атрибутов
starwars %>%
select(1:3) %>% slice(1:10) %>%
mutate(name_lag = lag(name)) %>%
mutate(name_lag2 = lag(name, n = 2)) %>%
mutate(name_lag3 = lag(name, n = 3, default = 'Frodo')) %>%
mutate(name_lag4 = lag(name, n = 3, order_by = mass))lead
Функция задает смещение вперед по вектору
lead(x, n = 1L, default = NULL, order_by = NULL, ...)
Рассмотрим смещение с разным набором атрибутов
starwars %>%
select(1:3) %>% slice(1:10) %>%
mutate(name_lag = lead(name),
name_lag2 = lead(name, n = 2),
name_lag3 = lead(name, n = 3, default = 'Frodo'),
name_lag4 = lead(name, n = 3, order_by = mass)
) Cumulative
cumall | cumany
Функции создают логические вектора с накопительным эффектом, т.е. до первого события
Как интерпретировать функции:
cum all(x): все случаи до первого FALSEcumall(!x): все случаи до первого значения TRUEcumany(x): все случаи после первого TRUEcumany(!x): все случаи после первого FALSE
Применение этих функций полезно с сочетании с фильтром, для того чтобы разделить выборку на до и после какого-то события и оставить либо часть, которая была ДО или часть после
df <- data.frame(
x = c(1, 3, 5, 2, 2)
)
df %>%
mutate(cumall = cumall(x < 5)) %>%
mutate(not_cumall = cumall(!(x < 5))) %>%
mutate(cumany = cumany(x < 5)) %>%
mutate(not_cumany = cumany(!(x < 5)))cummean
Функция вычисляет среднее значение накопительным итогом
df <- data.frame(
x = c(1, 3, 5, 2, 2)
)
df %>%
mutate(cummean = cummean(x))Следующие функции cummax, cummin, cumprod и cumsum относятся к базовому пакету R, но они также важны при рассмотрении оконных функций
cummax
Функция cummax определяет максимальное значение найденое в векторе к текущему элементу
df <- data.frame(
x = c(1, 3, 5, 2, 2)
)
df %>%
mutate(cummax = cummax(x))cummin
Функция cummin определяет минимальное значение найденое в векторе к текущему элементу
df <- data.frame(
x = c(1, 3, 5, 2, 2)
)
df %>%
mutate(cummin = cummin(x))cumprod
Функция cumprod перемножает элементы вектора накопительным итогом
df <- data.frame(
x = c(1, 3, 5, 2, 2)
)
df %>%
mutate(cumprod = cumprod(x))cumsum
Функция cumsum суммирует элементы вектора накопительным итогом
df <- data.frame(
x = c(1, 3, 5, 2, 2)
)
df %>%
mutate(cumsum = cumsum(x))Ranking
cume_dist
Функция cume_dist() подсчитывает общее количество значений, меньшее или равное i-му значению, и делит его на количество наблюдений
Рассмотрим пример по строчно:
x = 1- меньше или равно 1, только одно значение, а длина вектора 5: отсюда 1 / 5 = 0.2x = 3- меньше или равно 3, четыре значения, а длина вектора 5: отсюда 4 / 5 = 0.8x = 5- меньше или равно 5, пять значений, а длина вектора 5: отсюда 5 / 5 = 1x = 2- меньше или равно 2, три значения, а длина вектора 5: отсюда 3 / 5 = 0.6
df <- data.frame(
x = c(1, 3, 5, 2, 2)
)
df %>%
mutate(cume_dist = cume_dist(x))percent_rank
Функция percent_rank подсчитывает общее количество значений, меньших, чем x_i, и делит его на количество наблюдений минус 1
Рассмотрим пример по строчно:
x = 1- количество значений меньших чем x_i (x_i = 1) равно 0, отсюда 0 / 4 (5-1) = 0.00x = 3- количество значений меньших чем x_i (x_i = 3) равно 3, отсюда 3 / 4 (5-1) = 0.75x = 5- количество значений меньших чем x_i (x_i = 5) равно 4, отсюда 4 / 4 (5-1) = 1.00x = 2- количество значений меньших чем x_i (x_i = 2) равно 1, отсюда 1 / 4 (5-1) = 0.25
df %>%
mutate(percent_rank = percent_rank(x))row_number
Функция row_number присваивает каждой строке уникальный ранг
df %>%
mutate(row_number = row_number(x))min_rank
Функция min_rank присваивает каждой строке наименьший ранг, в зависимости от значения в строке
df %>%
mutate(min_rank = min_rank(x))dense_rank
Функция dense_rank работает как функция min_rank т.е. присваивает каждой строке наименьший ранг, в зависимости от значения в строке, но не делает пропусков в рангах
df %>%
mutate(dense_rank = dense_rank(x))ntile
Функция ntile присваивает каждой строке ранг, разбивая входной вектор на n сегментов. В отличие от других функций ранжирования, ntile() игнорирует связи: она создаст сегменты одинакового размера, даже если одно и то же значение x окажется в разных сегментах.
df %>%
mutate(ntile = ntile(x, 2))Агрегатные функции
summarise
Функция summarise создает новый фрейм данных. Он возвращает по одной строке для каждой комбинации группирующих переменных; если группирующих переменных нет, в выходных данных будет одна строка, суммирующая все наблюдения во входных данных. Он будет содержать по одному столбцу для каждой группирующей переменной и по одному столбцу для каждой из указанных вами сводных статистических данных.
С summarise применяются следующие функции:
- Center: mean(), median()
- Spread: sd(), IQR(), mad(), var()
- Range: min(), max(), quantile()
- Position: first(), last(), nth(),
- Count: n(), n_distinct()
- Logical: any(), all()
Center
mean
mean(x, trim = 0, na.rm = FALSE, ...) - арифметическое среднее
x- объект числовых/логических векторов и объектов date, date-time и time intervaltrim- доля (от 0 до 0,5) наблюдений, которая должна быть обрезана с каждого конца x перед вычислением среднего значения. Значения trim за пределами этого диапазона берутся в качестве ближайшей конечной точки.na.rm- логическое значение TRUE или FALSE, указывающее, следует ли удалять значения NA перед продолжением вычисления
x <- c(0:10, 50)
xm <- mean(x)
c(xm, mean(x, trim = 0.10))[1] 8.75 5.50median
median(x, na.rm = FALSE, ...) - медиана
na.rm- логическое значение TRUE или FALSE, указывающее, следует ли удалять значения NA перед продолжением вычисления
x <- c(0:10, 50)
median(x)[1] 5.5Spread
sd
sd(x, na.rm = FALSE) - стандартное отклонение
na.rm- логическое значение TRUE или FALSE, указывающее, следует ли удалять значения NA перед продолжением вычисления
x <- c(0:10, 50)
sd(x) ^ 2[1] 178.75IQR
IQR(x, na.rm = FALSE, type = 7) - вычисляет межквартильный диапазон значений x
na.rm- логическое значение TRUE или FALSE, указывающее, следует ли удалять значения NA перед продолжением вычисленияtype- выбор типа расчета квантиля (подробнее о типах расчета в ?quantile)
x <- c(0:10, 50)
IQR(x)[1] 5.5mad
mad(x, center = median(x), constant = 1.4826, na.rm = FALSE, low = FALSE, high = FALSE) - вычисляет среднее абсолютное отклонение, т.е. медиану абсолютных отклонений от медианы, и (по умолчанию) корректирует на коэффициент для получения асимптотически нормальной согласованности.
center- опционально можно задать центр, по умолчания используется медианаconstant- коэффициент масштабаna.rm- логическое значение TRUE или FALSE, указывающее, следует ли удалять значения NA перед продолжением вычисленияlow- если значение равно TRUE, вычисляет “lo-median”, т.е. для равномерного размера выборки не усредняет два средних значения, а берет меньшееhigh- если TRUE, вычисляет ‘hi-median’, т.е. берет большее из двух средних значений для равномерного размера выборки
x <- c(0:10, 50)
c(mad(x, constant = 1),
mad(x, constant = 1, low = TRUE),
mad(x, constant = 1, high = TRUE))[1] 3.0 2.5 3.5Range
min
min(..., na.rm = FALSE) - вычисляет минимальное значение
na.rm- логическое значение TRUE или FALSE, указывающее, следует ли удалять значения NA перед продолжением вычисления
x <- c(0:10, 50)
min(x)[1] 0max
max(..., na.rm = FALSE) - вычисляет наибольшее значение
na.rm- логическое значение TRUE или FALSE, указывающее, следует ли удалять значения NA перед продолжением вычисления
x <- c(0:10, 50)
max(x)[1] 50quantile
quantile(x, probs = seq(0, 1, 0.25), na.rm = FALSE, names = TRUE, type = 7, digits = 7, ...) - выдает выборочные квантили, соответствующие заданным вероятностям
x- числовой векторprobs- числовой вектор вероятностей со значениями в диапозоне [0, 1]na.rm- логическое значение TRUE или FALSE, указывающее, следует ли удалять значения NA перед продолжением вычисленияnames- если true, то результат имеет атрибут namestype- целое число от 1 до 9, выбор одного из девяти квантильных алгоритмов (подробнее в ?quantile)digits- точность, используемая при форматировании процентных значений, используются только в том случае, если значение names равно true
x <- c(0:10, 50)
quantile(x) 0% 25% 50% 75% 100%
0.00 2.75 5.50 8.25 50.00 Position
first
first(x, order_by = NULL, default = NULL, na_rm = FALSE)
x- векторorder_by- необязательный вектор того же размера, что и x, используемый для определения порядкаdefault- значение по умолчанию, используемое, если позиция не существует в x. Если значение по умолчанию равно NULL, то используется пропущенное значение. Если указано, это должно быть одно значение, которое будет приведено к типу x. Когда x является списком, по умолчанию допускается любое значение. В этом случае нет никаких ограничений по типу или размеру.na_rm- логическое значение TRUE или FALSE, указывающее, следует ли удалять значения NA перед продолжением вычисления
x <- c(0:10, 50)
first(x)[1] 0last
last(x, order_by = NULL, default = NULL, na_rm = FALSE)
x- векторorder_by- необязательный вектор того же размера, что и x, используемый для определения порядкаdefault- значение по умолчанию, используемое, если позиция не существует в x. Если значение по умолчанию равно NULL, то используется пропущенное значение. Если указано, это должно быть одно значение, которое будет приведено к типу x. Когда x является списком, по умолчанию допускается любое значение. В этом случае нет никаких ограничений по типу или размеру.na_rm- логическое значение TRUE или FALSE, указывающее, следует ли удалять значения NA перед продолжением вычисления
x <- c(0:10, 50)
last(x)[1] 50nth
nth(x, n, order_by = NULL, default = NULL, na_rm = FALSE)
x- векторn- целое число, указывающее позицию. Отрицательные целые числа индексируются с конца (т.е. -1L вернет последнее значение в векторе)order_by- необязательный вектор того же размера, что и x, используемый для определения порядкаdefault- значение по умолчанию, используемое, если позиция не существует в x. Если значение по умолчанию равно NULL, то используется пропущенное значение. Если указано, это должно быть одно значение, которое будет приведено к типу x. Когда x является списком, по умолчанию допускается любое значение. В этом случае нет никаких ограничений по типу или размеру.na_rm- логическое значение TRUE или FALSE, указывающее, следует ли удалять значения NA перед продолжением вычисления
x <- c(0:10, 50)
nth(x, 3)[1] 2Count
n
n() - возвращает количество элементов в каждой группе в виде набора данных
starwars %>%
summarise(n = n())n_distinct
n_distinct(..., na.rm = FALSE) - подсчитывает количество уникальных элементов
na_rm- логическое значение TRUE или FALSE, указывающее, следует ли удалять значения NA перед продолжением вычисления
x <- c(0:10, 50)
n_distinct(x)[1] 12Logical
any
any(..., na.rm = FALSE) - проверяет, есть ли в векторе хотя бы одного истинное значение
na_rm- логическое значение TRUE или FALSE, указывающее, следует ли удалять значения NA перед продолжением вычисления
x <- c(0:10, 50)
if (any(x == 9)) cat('В векторе есть число равное 9\n')В векторе есть число равное 9all
all(..., na.rm = FALSE) - проверяет все ли значения в векторе истинны
na_rm- логическое значение TRUE или FALSE, указывающее, следует ли удалять значения NA перед продолжением вычисления
x <- c(0:10, 50)
if (all(x >= 0)) cat('В векторе все значения больше или равны нулю\n')В векторе все значения больше или равны нулюУсловные функции и обработка Null
if_else
if_else векторизованная условная функция с возможность задать правило обработки Null значений
if_else(condition, true, false, missing = NULL, ..., ptype = NULL, size = NULL)
Аргументы:
- condition - логическое условие
- true - значение если условие True
- false - значение если условие False
- missing - значение если элемент равен Null
- ptype - желаемый тип вывода
- size - желаемый размер\длинна вывода
Рассмотрим пример когда относительно роста нужно распределить персонажей по ростовым категориям, а где значение роста равно Null присвоем другое значение
starwars %>%
slice(80:87) %>%
mutate(category = if_else(height < 100, "short", "tall", missing = "Неопределенный"), .keep = "used")case_when
Функция позволяет векторизовать несколько операторов if_else(). Каждый случай оценивается последовательно, и первое совпадение для каждого элемента определяет соответствующее значение в выходном векторе. Если ни один из вариантов не совпадает, используется значение .default.
case_when(..., .default = NULL, .ptype = NULL, .size = NULL)
В примере ниже показано как через одну функцию задать несколько разных условий по разным полям набора данных
starwars %>%
select(name, species, height, mass) %>%
mutate(
type = case_when(
height > 200 | mass > 200 ~ "large",
species == "Droid" ~ "robot",
.default = "other"
)
)case_match
Функция позволяет векторизовать несколько операторов switch(). Каждый случай оценивается последовательно, и первое совпадение для каждого элемента определяет соответствующее значение в выходном векторе. Если ни один из вариантов не совпадает, используется значение .default.
case_match(.x, ..., .default = NULL, .ptype = NULL)
В примере первым применением функции case_match обрабатываем NULL, во втором правим название типа персонажа
starwars %>%
mutate(
hair_color = case_match(hair_color, NA ~ "unknown", .default = hair_color),
species = case_match(
species,
"Human" ~ "Humanoid",
"Droid" ~ "Robot",
c("Wookiee", "Ewok") ~ "Hairy",
.default = species
),
.keep = "used"
)coaleasce
Функция находит первое не пропущенное значение и выводит его
coalesce(..., .ptype = NULL, .size = NULL)
В примере в новую колонку пишем первое не равное Null значение, сначала проверяем поле mass, если там Null проверяем поле height, если и в нем Null, то пишем нуль.
starwars %>%
slice(70:77) %>% select(name, mass, height) %>%
mutate(new_col = coalesce(mass, height, 0))na_if
Функция заменяет заданное значение на Null
na_if(x, y)
В примере заменяем значение 188 на Null
starwars %>%
slice(10:17) %>%
select(name, height) %>%
mutate(new_height = na_if(height, 188) )Обработка групп
group_by
group_by(.data, ..., .add = FALSE, .drop = group_by_drop_default(.data))
Функция group_by() позволяет группировать данные по одному или нескольким столбцам, создавая объект “grouped_df”. Она принимает в качестве аргументов имена столбцов или переменные, по которым нужно провести группировку.
Атрибуты:
.data- набор данных...- поля по которым необходимо сгруппировать набор.add = FALSE- при значении FALSE функция group_by() по умолчанию переопределяет существующие группы. Чтобы добавить в существующие группы, используйте .add = TRUE..drop = group_by_drop_default(.data)- удаляет группы, софрмированные по неотображаемым в наборе уровням фактора, по умолчанию TRUE
Пример использования:
# Создаем таблицу данных
df <- tibble(
group = rep(c("A", "B"), each = 3),
x = rnorm(6), y = rnorm(6)
)
df# Группируем данные по столбцу "group"
df_grouped <- df %>%
group_by(group)
df_grouped# Проверяем наличие группирующих переменных
df_grouped %>%
group_vars()[1] "group"В этом примере мы создали таблицу данных df с тремя столбцами: group, x и y. Затем мы использовали функцию group_by() для группировки данных по столбцу “group”, создав объект “grouped_df”. Наконец, мы использовали функцию group_vars чтобы проверить наличие в наборе группирующих переменных.
Метаданные групп
Функции из этого раздела дают дополнительную информацию о сгруппированном наборе данных и каждой отдельной группе внутри него.
group_data
group_data(.data)
Функция возвращает фрейм данных, который определяет структуру группировки. В столбцах приведены значения группирующих переменных. Последний столбец, всегда называемый .rows, представляет собой список целочисленных векторов, который указывает расположение строк в каждой группе. По сути объединяет в себе результат работы функций group_keys и group_rows.
starwars %>%
group_by(sex) %>%
group_data()group_keys
group_keys(.tbl, ...)
Функция возвращает набор данных описывающий группы
starwars %>%
group_by(sex) %>%
group_keys()group_rows
group_rows(.data)
Функция возвращает список целочисленных векторов, содержащих строки, которые содержит каждая группа.
starwars %>%
group_by(sex) %>%
group_rows()<list_of<integer>[5]>
[[1]]
[1] 5 7 27 41 44 52 58 61 62 63 67 70 71 76 83 87
[[2]]
[1] 16
[[3]]
[1] 1 4 6 9 10 11 12 13 14 15 17 18 19 20 21 23 24 25 26 28 29 30 31 32 33
[26] 34 35 36 38 39 42 43 45 46 47 48 49 50 51 53 54 55 56 57 59 60 64 65 66 68
[51] 69 72 74 75 77 78 79 81 82 84
[[4]]
[1] 2 3 8 22 73 85
[[5]]
[1] 37 40 80 86group_indices
group_indices(.data, ...)
Функция возвращает целочисленный вектор той же длины, что и набор данных, который указывает группу, к которой принадлежит каждая строка.
starwars %>%
group_by(sex) %>%
group_indices() [1] 3 4 4 3 1 3 1 4 3 3 3 3 3 3 3 2 3 3 3 3 3 4 3 3 3 3 1 3 3 3 3 3 3 3 3 3 5 3
[39] 3 5 1 3 3 1 3 3 3 3 3 3 3 1 3 3 3 3 3 1 3 3 1 1 1 3 3 3 1 3 3 1 1 3 4 3 3 1
[77] 3 3 3 5 3 3 1 3 4 5 1group_vars
group_vars(x) | groups(x)
Функция group_vars(x) возвращает вектор содержащий имена группирующих переменных, а функция groups(x) в виде списка
starwars %>%
group_by(sex) %>%
group_vars()[1] "sex"starwars %>%
group_by(sex) %>%
groups()[[1]]
sexgroup_size
group_size(x)
Функция возвращает количество элементов в каждой группе
starwars %>%
group_by(sex) %>%
group_size()[1] 16 1 60 6 4n_groups
n_groups(x)
Функция возвращает количество групп в наборе данных
starwars %>%
group_by(sex) %>%
n_groups()[1] 5Описание группы
n
n()
Функция возвращает количество элементов в каждой группе в виде набора данных
starwars %>%
group_by(sex) %>%
summarise(n = n())cur_group
cur_group()
Функция возвращает ключи группы для каждой группирующей переменной в виде tibble с одной строкой и столбцами количество которых равно количеству группирующих переменных
starwars %>%
group_by(sex, gender) %>%
mutate(data = list(cur_group())) cur_group_id
cur_group_id()
Функция задает уникальный идентификатор для текущей группы
starwars %>%
group_by(sex, gender) %>%
mutate(id = cur_group_id())cur_group_rows
cur_group_rows()
Функция задает индексы строк для текущей группы
starwars %>%
group_by(sex, gender) %>%
reframe(row = cur_group_rows()) cur_column
cur_column()
Функция возвращает имя текущего столбца и может применяться только с функцией across()
starwars %>%
select(8,2,3) %>%
group_by(sex) %>%
mutate(across(everything(), ~ paste(cur_column(), round(.x, 2))))Функции обработки групп
group_map
group_map(.data, .f, ..., .keep = FALSE)
group_map() - это функция, которая позволяет применить к каждой группе данных заданную пользователем функцию. Результатом функции является список, каждый элемент которого содержит результат выполнения функции .f для соответствующей группы данных. Эта функция может быть полезна, когда требуется выполнить некоторую операцию над каждой группой данных, например, построить график или вычислить статистику.
Аргументы:
- .tbl - группированный data frame;
- .f - функция, которую требуется применить к каждой группе данных;
- … - дополнительные аргументы, которые будут переданы в функцию .f.
Пример использования:
starwars %>%
group_by(sex) %>%
group_map(~ quantile(.x$height, probs = c(0.25, 0.5, 0.75), na.rm = T)) [[1]]
25% 50% 75%
164 166 174
[[2]]
25% 50% 75%
175 175 175
[[3]]
25% 50% 75%
173 183 193
[[4]]
25% 50% 75%
96 97 167
[[5]]
25% 50% 75%
180.5 183.0 183.0 К сгруппированному набору применяем функцию quantile и выводим список c результатами работы функции примененной к каждой группе.
group_modify
group_modify(.data, .f, ..., .keep = FALSE)
Эта функция используется для модификации каждой группы набора данных. В примере ниже сгруппируем набор по полю sex и в каждой группе оставим по одной верхней строке.
starwars %>%
group_by(sex) %>%
group_modify(~ head(.x, 1L))group_walk
group_walk(.data, .f, ..., .keep = FALSE)
Функция возвращает данные каждой группы и без изменений передает их дальше. Это можно использовать для выполнения действий с данными из каждой группы внутри процесса не нарушая логику алгоритма. В примере ниже мы выводим на печать первые две строки из каждой группы в виде отдельного tibble, а дальше применяем функцию group_modify как в примере выше.
В примере документации показан вариант, где данные каждой группы сохраняются в отдельный файл:`
group_walk(~ write.csv(.x, file = file.path(temp, paste0(.y$Species, ".csv"))))
Мы же выведем на печать первую строку из каждой группы, а дальше применить функцию модификации групп, оставив в каждой по 2 первые строки
starwars %>%
group_by(sex) %>%
group_walk(~ print(head(.x, 1L))) %>%
group_modify(~ head(.x, 2L))# A tibble: 1 × 13
name height mass hair_color skin_color eye_color birth_year gender homeworld
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Leia… 150 49 brown light brown 19 femin… Alderaan
# ℹ 4 more variables: species <chr>, films <list>, vehicles <list>,
# starships <list>
# A tibble: 1 × 13
name height mass hair_color skin_color eye_color birth_year gender homeworld
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Jabb… 175 1358 <NA> green-tan… orange 600 mascu… Nal Hutta
# ℹ 4 more variables: species <chr>, films <list>, vehicles <list>,
# starships <list>
# A tibble: 1 × 13
name height mass hair_color skin_color eye_color birth_year gender homeworld
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Luke… 172 77 blond fair blue 19 mascu… Tatooine
# ℹ 4 more variables: species <chr>, films <list>, vehicles <list>,
# starships <list>
# A tibble: 1 × 13
name height mass hair_color skin_color eye_color birth_year gender homeworld
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 C-3PO 167 75 <NA> gold yellow 112 mascu… Tatooine
# ℹ 4 more variables: species <chr>, films <list>, vehicles <list>,
# starships <list>
# A tibble: 1 × 13
name height mass hair_color skin_color eye_color birth_year gender homeworld
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Ric … 183 NA brown fair blue NA <NA> Naboo
# ℹ 4 more variables: species <chr>, films <list>, vehicles <list>,
# starships <list>group_cols
group_cols(vars = NULL, data = NULL)
Функция позволяет выбирать к поля по которым выполнялась группировка, обычно используется при выборке данных. Таким образом с помощью group_cols можно обратиться ко всем полям по которым выполнялась группировка.
starwars %>%
group_by(sex, gender) %>%
select(group_cols())group_split
group_split(.tbl, ..., .keep = TRUE)
Функция возвращает список отдельных групп данных, каждая из которых содержит только те строки, где значение переменных группировки соответствует данной группе.
В примере группируем набор по полю sex и разбиваем набор сформированным группам.
starwars %>%
group_by(sex) %>%
group_split()<list_of<
tbl_df<
name : character
height : integer
mass : double
hair_color: character
skin_color: character
eye_color : character
birth_year: double
sex : character
gender : character
homeworld : character
species : character
films : list
vehicles : list
starships : list
>
>[5]>
[[1]]
# A tibble: 16 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Leia Or… 150 49 brown light brown 19 fema… femin…
2 Beru Wh… 165 75 brown light blue 47 fema… femin…
3 Mon Mot… 150 NA auburn fair blue 48 fema… femin…
4 Shmi Sk… 163 NA black fair brown 72 fema… femin…
5 Ayla Se… 178 55 none blue hazel 48 fema… femin…
6 Adi Gal… 184 50 none dark blue NA fema… femin…
7 Cordé 157 NA brown light brown NA fema… femin…
8 Luminar… 170 56.2 black yellow blue 58 fema… femin…
9 Barriss… 166 50 black yellow blue 40 fema… femin…
10 Dormé 165 NA brown light brown NA fema… femin…
11 Zam Wes… 168 55 blonde fair, gre… yellow NA fema… femin…
12 Taun We 213 NA none grey black NA fema… femin…
13 Jocasta… 167 NA white fair blue NA fema… femin…
14 Shaak Ti 178 57 none red, blue… black NA fema… femin…
15 Rey NA NA brown light hazel NA fema… femin…
16 Padmé A… 165 45 brown light brown 46 fema… femin…
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
[[2]]
# A tibble: 1 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Jabba De… 175 1358 <NA> green-tan… orange 600 herm… mascu…
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
[[3]]
# A tibble: 60 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Luke Sk… 172 77 blond fair blue 19 male mascu…
2 Darth V… 202 136 none white yellow 41.9 male mascu…
3 Owen La… 178 120 brown, gr… light blue 52 male mascu…
4 Biggs D… 183 84 black light brown 24 male mascu…
5 Obi-Wan… 182 77 auburn, w… fair blue-gray 57 male mascu…
6 Anakin … 188 84 blond fair blue 41.9 male mascu…
7 Wilhuff… 180 NA auburn, g… fair blue 64 male mascu…
8 Chewbac… 228 112 brown unknown blue 200 male mascu…
9 Han Solo 180 80 brown fair brown 29 male mascu…
10 Greedo 173 74 <NA> green black 44 male mascu…
# ℹ 50 more rows
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
[[4]]
# A tibble: 6 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 C-3PO 167 75 <NA> gold yellow 112 none masculi…
2 R2-D2 96 32 <NA> white, blue red 33 none masculi…
3 R5-D4 97 32 <NA> white, red red NA none masculi…
4 IG-88 200 140 none metal red 15 none masculi…
5 R4-P17 96 NA none silver, red red, blue NA none feminine
6 BB8 NA NA none none black NA none masculi…
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
[[5]]
# A tibble: 4 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Ric Olié 183 NA brown fair blue NA <NA> <NA>
2 Quarsh P… 183 NA black dark brown 62 <NA> <NA>
3 Sly Moore 178 48 none pale white NA <NA> <NA>
4 Captain … NA NA unknown unknown unknown NA <NA> <NA>
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>group_trim
group_trim(.tbl, .drop = group_by_drop_default(.tbl))
Задача функции заключается в удалении неиспользуемых уровней факторов, которые используются в качестве переменных для группировки, а затем пересчёта структуры группировки.
Эта функция особенно полезна после применения функции filter(), которая выбирает подмножество групп. В результате применения filter() могут появиться неиспользуемые уровни факторов, что может привести к ошибкам или непредсказуемым результатам.
starwars %>%
group_by(sex) %>%
filter(sex == 'none') %>%
group_trim()rowwise
rowwise(data, ...)
Функция rowwise() позволяет выполнять вычисления для каждой строки входных данных. Это особенно полезно, когда векторизованная функция не подходит для вычислений. Вызов функции rowwise() создает так называемый “row-wise” data frame, в котором вычисления выполняются по каждой строке, сохраняя все переменные в строке.
В примере по строчно вычисляем наименьшее значение из трех числовых столбцов
starwars %>%
select(c(1,2,3,7)) %>%
rowwise() %>%
mutate(m = min(c(height, mass, birth_year)))c_across
c_across(cols)
Функция применяется с rowwise для упрощения агрегирования по строкам. Для формирования выходного результата используется vctrs::vec_c().
df <- tibble(id = 1:4, w = runif(4), x = runif(4), y = runif(4), z = runif(4))
df %>%
rowwise() %>%
mutate(
sum = sum(c_across(w:z)),
sd = sd(c_across(w:z))
)ungroup
ungroup(x, ...)
Функция удаляет группировку из набора данных
# группируем набор по двум полям
starwars %>%
group_by(sex, gender) %>%
# проверяем наличие группирующих переменных
group_vars()[1] "sex" "gender"# группируем набор по двум полям
starwars %>%
group_by(sex, gender) %>%
# удаляем группировку
ungroup() %>%
# проверяем наличие группирующих переменных
group_vars()character(0)reframe
reframe(.data, ..., .by = NULL)
функция создает новый фрейм данных, применяя функции к столбцам существующего фрейма данных. Отличается от summarise() тем, что может возвращать произвольное количество строк для каждой группы и всегда возвращает несгруппированный фрейм данных. reframe() может быть особенно полезен, когда вам нужно применить сложную функцию, которая не возвращает ни одного суммарного значения.
table <- c("a", "b", "d", "f")df <- tibble(
g = c(1, 1, 1, 2, 2, 2, 2),
x = c("e", "a", "b", "c", "f", "d", "a")
)df %>%
reframe(x = intersect(x, table))Объединение таблиц
В процессе объединения таблиц можно выделить операции трех видов:
- Mutating joins, которые добавляют новые переменные в один фрейм данных из совпадающих наблюдений в другом.
- Filtering joins, которые фильтруют наблюдения из одного фрейма данных на основе того, соответствуют ли они наблюдению в другой таблице.
- Set operations, эти операции работают с пересечениями двух фреймов
Для разбора операций соединения, загрузим набор данных nycflights13
```{r}
library(nycflights13)
```Ключи соединения
Сопоставление ключей
При соединении фреймов данных нужно указать ключи соединения иногда это может быть один ключ или набор ключей, они могут совпадать по наименованию или различаться. Давайте рассмотрим разные варианты.
Соединить по всем совпадающим полям
Чтобы соединить по всем совпадающим по названию полям, нужно оставить by = NULL
flights2 %>%
left_join(weather)Joining with `by = join_by(year, month, day, origin, hour, time_hour)`Соединить по одному ключу
Соединение по одному ключу с общим для обоих фреймов названием:
flights2 %>%
left_join(planes, by = "tailnum")Соединить по нескольким ключам
- by = c(“a” = “b”) ->
x$a == y$b- соединить с помощью разных переменных на x и y, используется именованный вектор. - by = c(“a”, “b”) ->
x$a == y$a and x$b == y$b- соединить по нескольким переменным - by = c(“a” = “b”, “c” = “d” ->
x$a == y$b and x$c == y$d- соединить сопоставив раличные переменные из двух фреймов
flights2 %>%
left_join(airports, c("dest" = "faa"))Проблемы с ключами
Не всегда бывает так, что значения в ключевом столбце уникальные. Когда соединяются дублированные ключи, получаются все возможные комбинации, декартово произведение. В функции Join нет никакой обработки таких случаев, поэтому нужно быть внимательным к своим данным и проверять результирующий набор данных. А также при необходимости удалять дублирующие строки.
Убедитесь, что ваши внешние ключи совпадают с первичными ключами в другой таблице. Лучший способ сделать это - с помощью anti_join(). Часто ключи не совпадают из-за ошибок ввода данных. Их устранение часто требует большой работы.
Mutating joins
В принципе это самые обычные и привычные Join-ы, которые мы используем каждый день. Рассмотрим аргументы этих функций:
- x, y - пара фреймов данных, которые нужно соединить
- by - вектор переменных в котором задаются ключи
- suffix - добавляет суффиксы для одноименных не ключевых полей
- keep - указывает, нужно ли сохранять ключевые поля в результирующем фрейме данных
- na_matches - задает считать или нет равными значения NA и NaN, по умолчанию “na” считаются равными, “never” - исчтать не равными
Чтобы понять суть разных типов соединений, создадим два тестовых фрейма данных и проиллюстрируем на их примере каждый тип:
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
3, "x3"
)
y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2",
4, "y3"
)
x
yInner join
Внутреннее соединение сопоставляет пары наблюдений всякий раз, когда их ключи равны.Наиболее важным свойством внутреннего соединения является то, что несогласованные строки не включаются в результат. Это означает, что, как правило, внутренние соединения обычно не подходят для использования в анализе, потому что слишком легко потерять наблюдения.
```{r}
inner_join(
x,
y,
by = NULL,
copy = FALSE,
suffix = c(".x", ".y"),
...,
keep = FALSE,
na_matches = c("na", "never")
)
```xy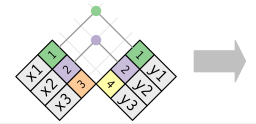
inner_join(x, y, by = "key")Outer joins
Внешнее соединение сохраняет наблюдения, которые отображаются по крайней мере в одной из таблиц.
Left Join
left_join - сохраняет все строки из первой таблицы и соединяет все совпавшие по ключу строки из второй таблицы.
Наиболее часто используемым соединением является левое соединение: его используют всякий раз, когда просматривают дополнительные данные из другой таблицы, потому что оно сохраняет исходные наблюдения, даже если совпадения нет. Левое соединение должно быть соединением по умолчанию: используйте его, если у нет веских причин предпочесть одно из других.
```{r}
left_join(
x,
y,
by = NULL,
copy = FALSE,
suffix = c(".x", ".y"),
...,
keep = FALSE,
na_matches = c("na", "never")
)
```Разберем подробнее левое соединение:
xy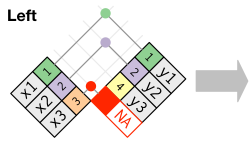
left_join(x, y, by = "key")Right Join
right_join - сохраняет все строки из второй таблицы и соединяет все совпавшие по ключу строки из первой таблицы
```{r}
right_join(
x,
y,
by = NULL,
copy = FALSE,
suffix = c(".x", ".y"),
...,
keep = FALSE,
na_matches = c("na", "never")
)
```xy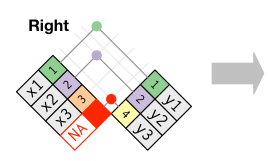
right_join(x, y, by = "key")Full Join
full_join - сохраняет все строки из обоих таблиц
```{r}
full_join(
x,
y,
by = NULL,
copy = FALSE,
suffix = c(".x", ".y"),
...,
keep = FALSE,
na_matches = c("na", "never")
)
```xy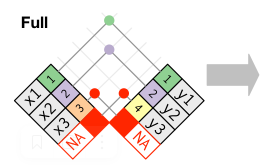
full_join(x, y, by = "key")Filtering joins
Фильтрующие соединения используются для фильтрации первого фрейма на основе данных из второго фрейма данных.
semi_join
semi_join соединяет две таблицы подобно мутирующему соединению, но вместо добавления новых столбцов сохраняет только те строки в x, которые совпадают в y.
xy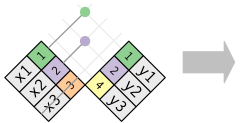
semi_join(x, y, by = "key")Важно только наличие совпадения; не имеет значения, какому наблюдению соответствует. Это означает, что фильтрующие соединения никогда не дублируют строки, как это делают мутирующие соединения.
anti_join
Антисоединения полезны для диагностики несоответствий соединений. Например, так можно делать проверку полноты данных по эталонным справочникам:
xy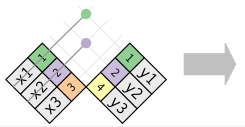
anti_join(x, y, by = "key")nest_join
nest_join() возвращает все строки и столбцы в x с новым столбцом в каждой строке которого вложен фрейм, содержащий все совпадения из y. Если совпадений нет, то фрейм будет пустой.
xynest_join(x, y, by = "key")nest_join(x, y, by = "key") %>%
unnest(cols = c(y))Set operations
Операции с наборами требуют чтобы соединяемые фреймы данных имели одинаковое количество столбцов, эти функции объединяют два фрейма данных как бы складывая их друг под друга.
Создадим два фрейма, чтобы показать работу этих функций:
df1 <- tribble(
~x, ~y,
1, 1,
2, 1
)
df2 <- tribble(
~x, ~y,
1, 1,
1, 2
)union
- union - оставляет только уникальные строки из обоих наборов
- union_all - оставляет все строки из обоих наборов
df1df2union(df1, df2)union_all(df1, df2)intersect
оставляет только совпавшие строки из обоих наборов:
df1df2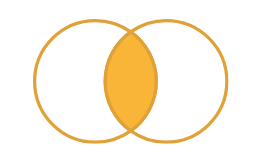
intersect(df1, df2)setdiff
оставляет строки из первого фрейма только не совпавшие со строками из второго фрейма
df1df2
setdiff(df1, df2)setdiff(df2, df1)Манипуляция отдельными строками
Группа этих функций позволяет манипулировать отдельными строками на подобии SQL без создания копии фрейма данных. Каждая строка представляет из себя фрейм с одной или более строк.
Рассмотрим атрибуты функций:
x, y- пара фреймов,xисходный фрейм, аyфрейм-строка, с которой нужно выполнить операцию.yдолжен иметь те же столбцы, чтоxby- задание ключевых столбцов. Ключи обычно однозначно идентифицируют каждую строку, но это применяется только для значений ключа y, когда используются rows_update(), rows_patch() или rows_upsert(), по умолчанию используется первый столбец вyconflict- правило для обработки конфликтов вставки при использованииrows_insert(). Конфликт возникает, если вyесть ключ, который уже существует вx. Можно задать два типа поведения:error- значение по умолчанию, приведет к ошибке, если вyесть какие-либо ключи, которые конфликтуют с ключами вx;ignore- будет игнорировать строки вyс ключами, которые конфликтуют с ключами вxcopy- еслиxи ьyне из одного источника данных и значениеcopyравно TRUE, тоyбудет скопирован в тот жеsrc, что иx. Это позволяет объединять таблицы в разныхsrc, но это потенциально дорогостоящая операцияunmatched- правило для обработки ключей вyне совпадающих с ключами вx, используется в rows_update(), rows_patch(), and rows_delete(). Можно задать два типа поведения:error- значение по умолчанию, вызовет ошибку если ключи не совпадают;ignore- будет игнорировать строки с несовпадающими ключами
Создадим набор данных для описания возможностей работы с функциями:
data <- tibble(a = 1:3, b = letters[c(1:2, NA)], c = 0.5 + 0:2)
datarows_insert
rows_insert(x, y, by = NULL, ..., conflict = c("error", "ignore"), copy = FALSE, in_place = FALSE)
rows_insert() - добавляет новую стороку во фрейм данных, по умолчанию ключевые значения добавляемой строки не должны существовать во фрейме.
rows_insert(data, tibble(a = 4, b = "z"))Matching, by = "a"rows_insert(data, tibble(a = 3, b = "z"), conflict = "ignore")Matching, by = "a"Воспроизведем ситуацию когда ключевые значения совпадают, и функция не дополнена аргументом conflict
try(rows_insert(data, tibble(a = 3, b = "z")))Matching, by = "a"Error in rows_insert(data, tibble(a = 3, b = "z")) :
`y` can't contain keys that already exist in `x`.
ℹ The following rows in `y` have keys that already exist in `x`: `c(1)`.
ℹ Use `conflict = "ignore"` if you want to ignore these `y` rows.rows_append
rows_append(x, y, ..., copy = FALSE, in_place = FALSE)
rows_append() - добавляет новую стороку во фрейм данных, в отличии от rows_insert() игнорирует ключи
rows_append(data, tibble(a = 7, b = "n"))rows_update
rows_update(x, y, by = NULL, ..., unmatched = c("error", "ignore"), copy = FALSE, in_place = FALSE)
rows_update() - изменяет существующие строки. Значения ключей в y должны быть уникальными, и, по умолчанию, значения ключей в y должны существовать в x
rows_update(data, tibble(a = 1, b = "s", c = 11.4), by = "a")rows_patch
rows_patch(x, y, by = NULL, ..., unmatched = c("error", "ignore"), copy = FALSE, in_place = FALSE)
rows_patch() - изменяет существующие строки и перезаписывает только NA значения
rows_patch(data, tibble(a = 3, b = "s", c = 11.4), by = "a")rows_upsert
rows_upsert(x, y, by = NULL, ..., copy = FALSE, in_place = FALSE)
rows_upsert() - вставляет или обновляет строку в зависимости от того, существует ли ключевое значение из y в x или нет
rows_upsert(data, tibble(a = c(1, 4), b = c("s", "e"), c = c(11.4, 3.01)), by = "a")rows_delete(
rows_delete(x, y, by = NULL, ..., unmatched = c("error", "ignore"), copy = FALSE, in_place = FALSE)
rows_delete() - удаляет строки из фрейма x, по умолчанию ключи из y должны быть в x
rows_delete(data, tibble(a = 1:2))Matching, by = "a"Производительность
https://arrow.apache.org/docs/format/Columnar.html
https://www.tidyverse.org/blog/2023/04/performant-packages/
https://adv-r.hadley.nz/introduction.html
http://adv-r.had.co.nz/Performance.html
Citation
BibTeX citation:
@online{practices it2022,
author = {Practices IT, Best},
title = {Dplyr},
date = {2022-11-16},
langid = {en}
}
For attribution, please cite this work as:
Practices IT, Best. 2022. “Dplyr.” November 16, 2022.